
AES-256
端到端加密
在传输中(TLS 1.3)与存储中(AES-256)对所有存储与处理环节加密 – 源文件不会以未受保护的方式流动。
全生命周期的数据管理,加速从原始信息到高性能 AI 模型的路径。我们将专家领域知识与严谨验证同步推进,把非结构化数据转化为完全工程化、高保真度的智能资产 – 确保平稳过渡到生产环境,在最大化模型准确率的同时减少在数据排错上的时间投入。
标注不到位或不一致的数据集,会带来瓶颈、降低准确率、并放大下游修复错误的成本。下面就是数据质量真正改变指标的方式。
图示数据来自不同客户项目,实际提升因用例与基线质量而异。
准确的数据带来更好的决策与更可靠的结果。
清晰的指南、可量化的标注一致性、定期校准评审 – 让一致性可规模化。
每一份文件在交到您手上之前,都会经过 2–3 层 QA 复核。
选择一种模态,即可预览我们的输出方式。每种格式都附带完整的标注指南、标注一致性报告以及 QA 通过的真值数据。
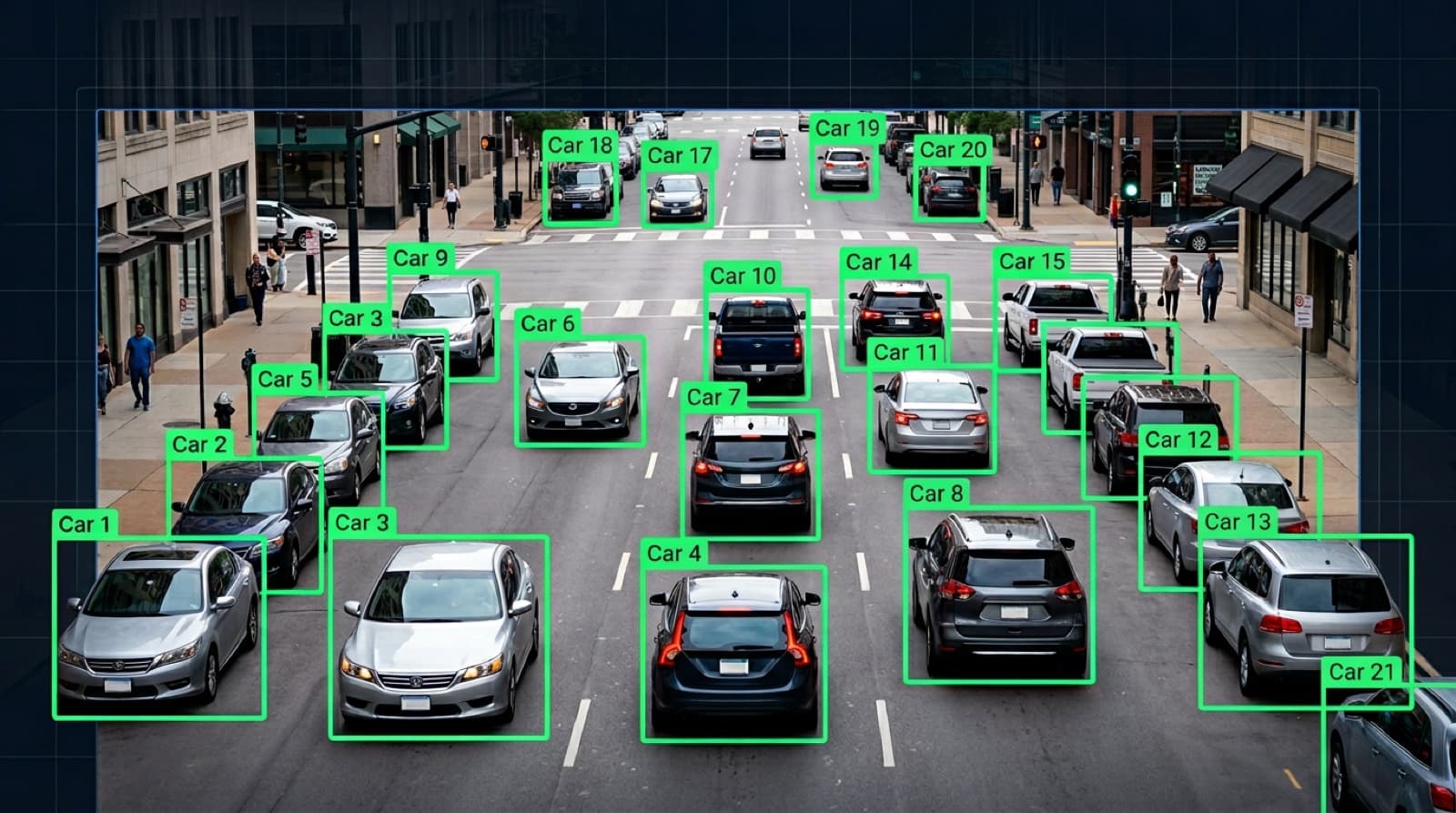
覆盖分类、检测、分割任务的像素级精确标注 – 任何计算机视觉模型的基础。




每一次合作都遵循同样的纪律 – 不会让您困惑当下进度、下一步是什么,以及如何衡量质量。
了解您的目标、项目范围、数据类型与质量要求。
对源数据进行采集、清洗、整理与预处理。
明确标注规则、边缘情况与质量标准。
围绕指南、流程与产出质量对标注师进行培训。
按照获批的指南与项目规范对数据进行标注。
2–3 层复核流程,识别错误并保持准确率。
以 AI 就绪的格式交付经验证的标注成果。
安全、隐私与治理融入每一次合作 – 从首日 NDA 到加密交付与可验证删除。
在传输中(TLS 1.3)与存储中(AES-256)对所有存储与处理环节加密 – 源文件不会以未受保护的方式流动。
首日即签署双方 NDA,标注师在接触任何数据之前需遵守项目级保密与桌面整洁政策。
工作流对齐 GDPR、越南 PDPL 与澳大利亚《隐私法》 – 个人信息按照明文规定的留存、地域与披露规则处理。
最小权限访问、所有账户启用 MFA、按项目划分权限范围 – 标注师只能看到任务所需的数据。
每一次变更都有据可查 – 谁、何时、做了什么、为何而做。版本化指南与逐批次的一致性指标随每次交付一同提供。
在合同约定的时间节点清除数据,并通过加密擦除确认 – 不会保留超出合作所需的任何内容。
纪律、灵活性与硬指标 – 这些是团队反复信赖我们的原因。
结构化项目管理、版本化指南与审计轨迹 – 适用于受监管行业。
从单批次标注到长期标注运营 – 可灵活扩缩,无需合同上的拉锯。
图像、视频、文本、音频、文档与 3D – 一支团队、一个对接人,覆盖所有模态。
2–3 层复核与可量化的标注一致性 – 每个数据集均附带质量报告。
从 1 万行到 1000 万行 – 借助弹性标注团队与批量 QA,保持稳定的交付节奏。
全球 60+ 团队信赖 – 我们既懂数据工程师的语言,也懂机器学习研究者的语言。
Beyond core annotation, DataX Power runs managed collection programs for teams with specific hardware, scenario, or scale requirements.
Custom egocentric, multi-sensor, and teleoperation video datasets for humanoid robots, embodied AI, and VLA models. End-to-end managed programs from APAC.
Explore this serviceFull managed data collection programs - video, multi-sensor, teleoperation, field, and audio. APAC-native execution with QA for humanoid robots, ADAS, and enterprise AI.
Explore this service我们的注释团队接受过针对特定领域标记任务的培训,而不仅仅是一般图像和文本注释。这些是我们维持活跃生产计划的垂直领域。
覆盖标注、分析与数据产品的四个项目 – 每一个数据集背后都有可衡量的业务成果。
您选定平台,我们提供训练有素的标注员。客户偏好交钥匙时,我们也运营自有的基于 Kili 的流水线。
关于 DataX Power 越南数据标注服务的实际问题与解答。



